
Hadoop安装和配置
实验目的及要求
- 掌握 Hadoop 集群环境的搭建方法,熟悉了解一些典型的 Hadoop 操作命令
- 熟悉使用 Hadoop 伪分布模式的配置
实验环境
宿主机配置为 Intel® Core™ i7-8700 CPU @ 3.20GHz,8G Mem,1T HDD,Intel VT 硬件虚拟化已开启
真实系统为 Ubuntu 20.04.1 x64 (Linux version 5.13.0-39-generic)
实验步骤
第一步:检查JAVA环境安装和JAVA_HOME环境变量配置
- 查看 JAVA 是否成功安装
java -version
# 有版本信息输出则表示已安装(也不一定,有可能相关工具包没装),直接跳到第3小步

- 安装 JAVA 环境(若上一步已确认成功安装,则跳过此步骤)
sudo apt-get install openjdk-8-jdk
- 配置系统变量 JAVA_HOME
# 需要以root用户身份进行设置
su root
# 设置环境变量,参数需根据当前Java安装目录和版本来定
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 >> /etc/profile
# 重新加载一下环境变量
source /etc/profile
- 执行下面的命令看系统变量 JAVA_HOME 是否配置成功
echo $JAVA_HOME
# 有输出且内容为上一步设置的参数
第二步:下载并解压 Hadoop 源码
- 下载 Hadoop 发行版源码文件
wget https://mirrors.bit.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
- 解压 Hadoop 源码文件
tar xf hadoop-2.10.1.tar.gz
cd hadoop-2.10.1
第三步:编辑 Hadoop 相关配置文件
- 编辑 hadoop-env.sh 配置文件
vim etc/hadoop/hadoop-env.sh
# 找到export JAVA_HOME一行,修改为如下内容
# export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 编辑 core-site.xml 配置文件
vim etc/hadoop/core-site.xml
- 具体修改内容如下:(设置HDFS端口号,注意端口号值,以防冲突)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9080</value>
</property>
</configuration>
- 编辑 hdfs-site.xml 配置文件
vim etc/hadoop/hdfs-site.xml
- 具体修改内容如下:(设置副本数量,默认为3)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四步:安装OpenSSH-server 并配置 SSH 无密钥登录
sudo apt-get install openssh-server
ssh-keygen -t dsa
# 默认回车结束
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
第五步:格式化 HDFS 文件系统
# 确保在 hadoop-2.10.1 目录下执行
bin/hdfs namenode -format
第六步:启动 NameNode 和 DataNode 守护进程
sbin/start-dfs.sh
# 你可以使用如下命令查看是否启动成功
jps

第七步:在HDFS上进行文件操作
- 在HDFS中创建名为 miao 的目录
bin/hdfs dfs -mkdir /miao
bin/hdfs dfs -ls /
- 在本地目录下创建一个 miao.txt 的文本文件(文本内容自定),并复制到HDFS中
vim miao.txt
bin/hdfs dfs -put miao.txt /miao/
# 如遇到 safe mode 错误,尝试以下命令重试
bin/hadoop dfsadmin -safemode leave
实验小结
通过安装 Hadoop 并配置集群环境,掌握了 Hadoop 伪分布模式的配置,了解了一些典型的 Hadoop 操作命令,为之后MapReduce实验奠定了良好的基础,同时也对分布式计算的基本原理有了更加深入的理解。
MapReduce:单词计数案例实践
实验目的及要求
- 熟悉MapReduce流程,完成单词计数案例实践
实验环境
宿主机配置为 Intel® Core™ i7-8700 CPU @ 3.20GHz,8G Mem,1T HDD,Intel VT 硬件虚拟化已开启
真实系统为 Ubuntu 20.04.1 x64 (Linux version 5.13.0-39-generic)
实验步骤
第一步:安装 JAVA 项目构建工具 Maven,并配置仓库
- 安装构建工具 Maven
sudo apt-get install maven
- 更新 maven 仓库地址
# 检查当前用户主目录下是否存在 .m2 目录,若不存在自己新建
cd ~
ls -la
mkdir .m2
# 检查 .m2 目录下是否存在 settings.xml 文件,若不存在则从/etc/maven下拷贝相关文件
cp /etc/maven/settings.xml ~/.m2/
vim ~/.m2/settings.xml
- 找到 <mirrors> </mirrors> 位置,并在其中添加如下内容:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
第二步:创建项目
- 配置 maven 创建项目
nkdir maven-project
cd maven-project
# 项目文件名为 wordcount 包名自定义
mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=cn.edu.seu.zys -DartifactId=wordcount -DpackageName=cn.edu.seu.zys -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
- 更新 pom.xml 文件添加对 Hadoopd 的依赖
cd wordcount
vim pom.xml
- 在 <dependencies> </dependencies> 中添加如下内容:
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
<scope>provided</scope>
</dependency>
- 在 </dependencies> 后面添加如下内容
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
- 下载依赖文件
mvn clean install -DskipTests
第三步:编写 wordcount 程序源码
# 当前目录:maven-project/wordcount/
# 具体路径取决于包名中自定义名称而定
touch src/main/java/cn/edu/seu/zys/WordCount.java
vim src/main/java/cn/edu/seu/zys/WordCount.java
- 具体代码如下(注意修改第一行包名)
package cn.edu.seu.zys;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper < Object, Text, Text, IntWritable > {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)throws IOException,
InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer < Text, IntWritable, Text, IntWritable > {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable < IntWritable > values,
Context context)throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val: values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[]args)throws Exception {
Configuration conf = new Configuration();
String[]otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第四步:打包 Jar 文件
mvn clean install -DskipTests
第五步:提交任务并且运行
cd hadoop-2.10.1
# 根据自己实际路径输入以下命令
bin/hadoop jar ../maven-project/wordcount/target/wordcount-1.0-SNAPSHOT.jar cn.edu.seu.zys.WordCount /miao/miao.txt /miao/output/
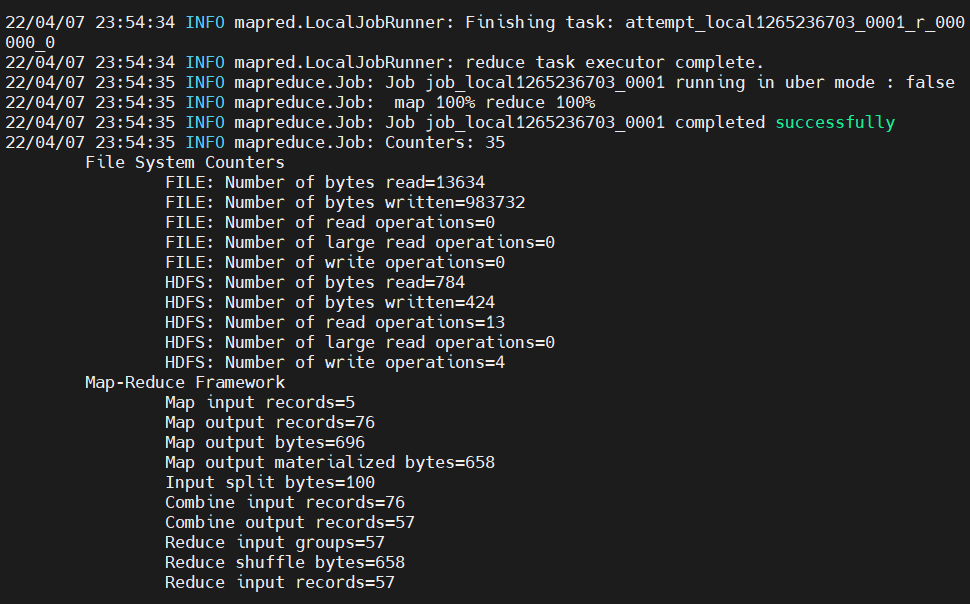
第六步:检查实验结果
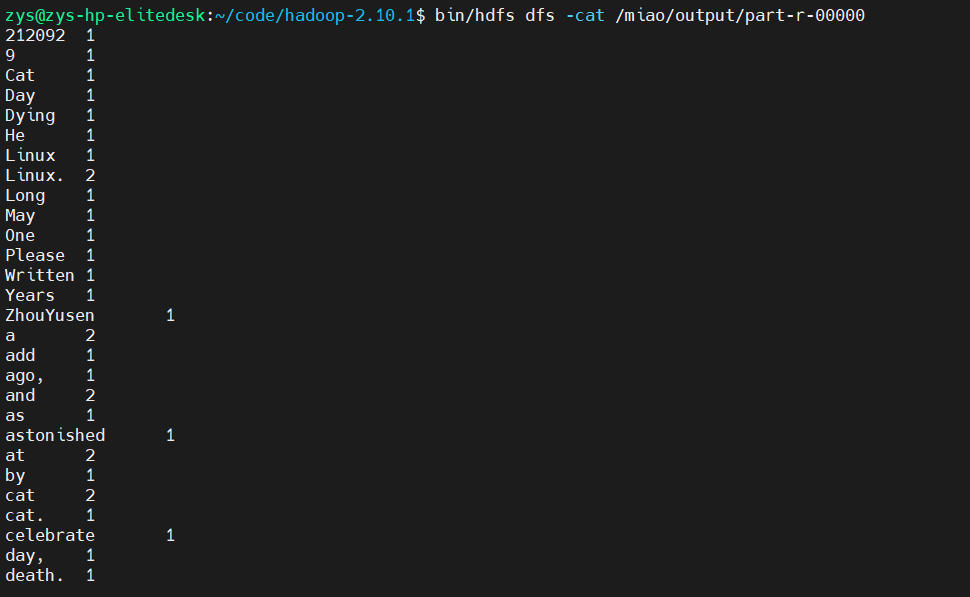
bin/hdfs dfs -ls /miao/output
bin/hdfs dfs -cat /miao/output/part-r-00000
# 重新运行,需删除输出文件,否则会报错
bin/hdfs dfs -rm -r /miao/output
实验小结
通过单词计数的案列实践,对MapReduce的基本原理和使用操作有了更加清醒的认识,同时也对构建工具 Maven 的使用有了进一步的了解,掌握了其创建项目、管理依赖、编译项目的基本功能的使用。另外,对分布式文件系统 HDFS 的使用更加熟练,掌握了其基本的文件操作命令。

